はじめに
初めまして、4月からアスクルに新卒入社しました、「みわすけ」です。
新卒エンジニアとして、まだまだ勉強中ではありますが、今回ヤフーさん主催の「Yahoo! JAPAN Internal Hack Day 17」というイベントに参加させていただきました。
HackDayとは
テクノロジーを、もっと身近に、もっと楽しく。Hack Dayは、ものづくりの面白さを体験する祭典です。日本最大級のハッカソンや、注目のコンテンツを揃えた体験ブースなど、盛りだくさんのイベントを毎年開催しています。(https://hackday.jp より)
その中で、我々アスクルチームは会議の議事録を取る行為をエンジニアリングで解決しようとなり、24時間で開発していきました。この記事ではその中で「発言を文字起こしする」部分に使用したGoogleのCloud Sppech-to-Textの使い方について解説します。
開発環境
Python 3.7.6
API準備
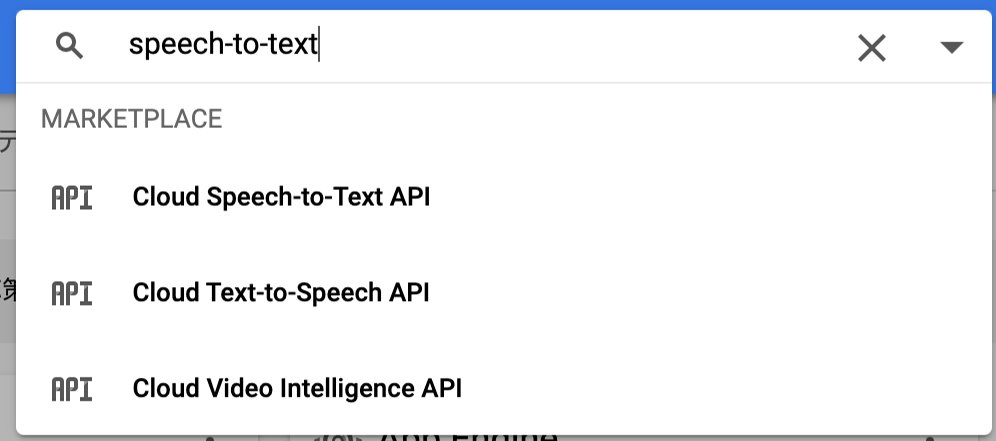
はじめにGoogle Cloud Platform(以下GCP)にてSpeech-to-Text APIを有効にします。
「プロダクトとリソースの検索」
から「Cloud Speech-to-Text」を検索しAPIを有効にします。
Speech-to-Textの利用準備はこれで完了です。
パッケージのインストール
次にpipを使い必要なパッケージのインストールをしていきます。
$ pip install google gcloud google-auth grpc.google.cloud.speech-v1 grpc-google-cloud-speech-v1beta1
上記の他にPythonで音声を扱うためのパッケージ、pyaudioもインストールしたいのですがPython3.7.6環境だとインストールできないのでwhlファイルを直接ダウンロードしてきてインストールします。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
こちらのurlから環境に合ったファイルをダウンロードしてきて、
$ pip install whlファイル
でインストールします。
どのファイルをダウンロードすればいいかは、
from pip._internal.utils.compatibility_tags import get_supported print(get_supported())
で確認できます。
Successfuly install pyaudioが出力されたらインストール完了です。
実行準備
にストリーミング 入力のためのサンプルコードがあるのでコピー、今回はspeech.pyという名前で保存しています。
language_code = 'en-US
言語が英語になっているので次に変更します。
language_code = 'ja-JP
サンプルのimport文だとenumがインポートできないとエラーが出ます。
Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: cannot import name enums
そのためサンプルのこの部分をspeech_v1をインポートするように変更します。
from google.cloud import speech from google.cloud.speech import enums from google.cloud.speech import types
from google.cloud import speech_v1 as speech from google.cloud.speech_v1 import enums from google.cloud.speech_v1 import types
実行
streamオプションを付けて実行します。
$ speech.py stream //省略 warning _CLOUD_SDK_CREDENTIALS_WARNING
認証エラーが出るのでGCPでサービスアカウントキーの取得が必要になります。
サービスアカウントキーの生成
GCPから「APIとサービス > 認証情報 > 認証情報の作成 > サービスアカウント」から適当な名前とIDを付け生成します。
作成されたjsonファイルを環境変数として利用します。
set GOOGLE_APPLICATION_CREDENTIALS=servicekey.json
これで事前準備はすべて完了です。
実行
実行してマイクに向かって話した結果です。
動作テスト
alternatives {
transcript: "\345\213\225\344\275\234\343\203\206\343\202\271\343\203\210"
confidence: 0.9614928364753723
words {
start_time {
seconds: 1
nanos: 800000000
}
end_time {
seconds: 2
nanos: 300000000
}
word: "\345\213\225\344\275\234|\343\203\211\343\203\274\343\202\265"
speaker_tag: 1
}
words {
start_time {
seconds: 2
nanos: 300000000
}
end_time {
seconds: 2
nanos: 500000000
}
word: "\343\203\206\343\202\271\343\203\210|\343\203\206\343\202\271\343\203\210"
speaker_tag: 1
}
}
is_final: true
result_end_time {
seconds: 3
nanos: 140000000
}
こちらのコードで結果を取得。
result.alternatives[0].transcript
configに以下を追記することで結果に speaker_tag も追加され発言者の特定も可能になります。
config = types.RecognitionConfig(
# その他設定
diarization_config = types.SpeakerDiarizationConfig(
enable_speaker_diarization = True
)
)
ハッカソンではこちらを利用し、議事録を取ってくれるwebアプリを作成しました。
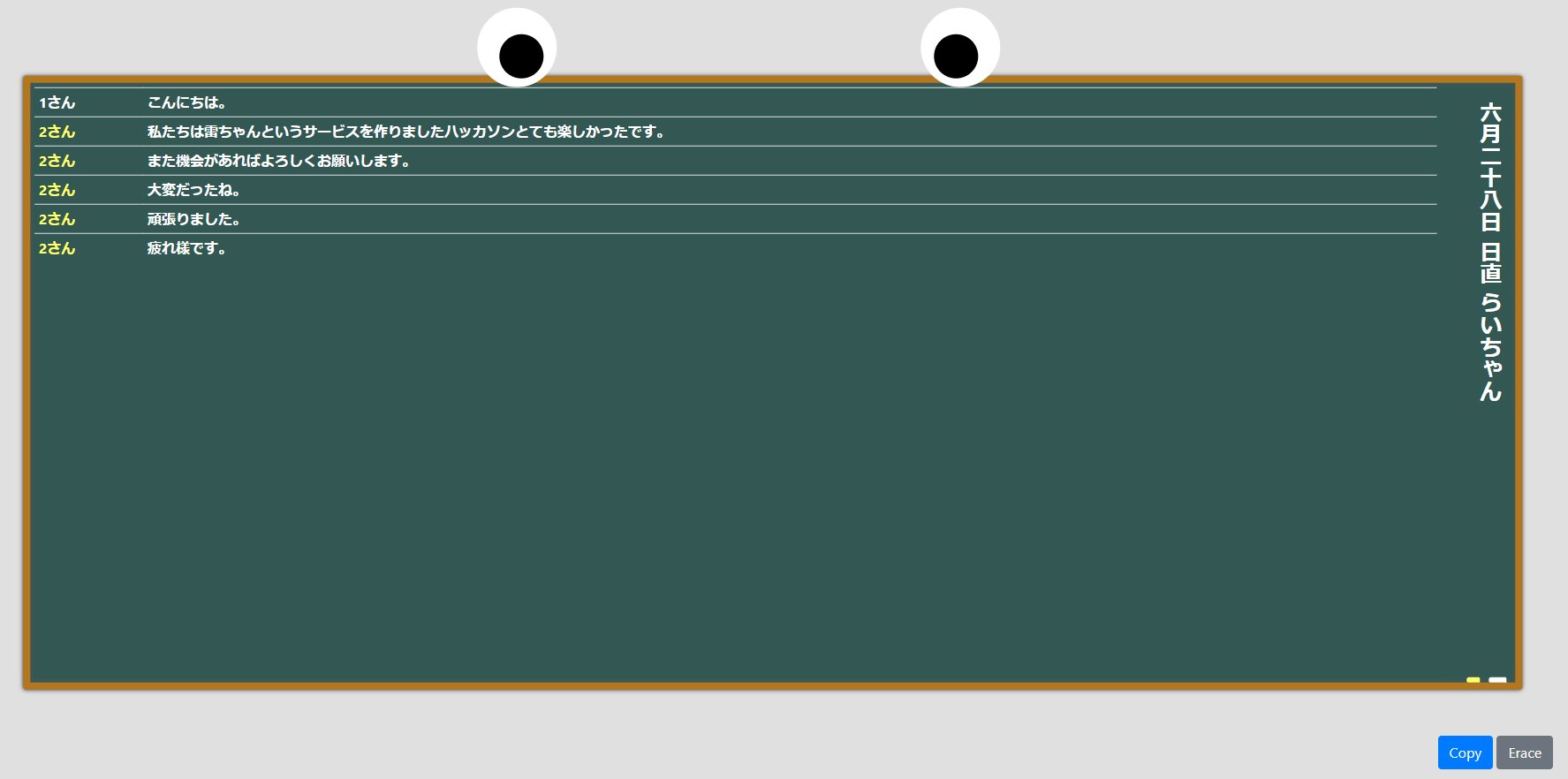
最後に
私はハッカソン初参加でしたが。
「テクノロジーを、もっと身近に、もっと楽しく」
という趣旨のとおり身近な課題をテクノロジーで楽しく解決できたと思っています。また機会があれば参加したいと思える楽しいイベントでした。 以上になります、最後までお読みいただきありがとうございます。